1分鍾30大元。
做過 Up 主、YouTuber 或是視頻自媒體從業者都知道,一部傳到平台上 10 分鍾的成片,背後可能是幾個小時的素材。如同快充般的「拍攝 1 小時,剪出 1 分鍾」。而在電影行業,常見素材比也在 10:1 到 20:1 甚至更高。
那些被棄用的素材叫做「廢片」,在成片輸出後,這些素材就如同廢品一樣,留著隻會占據硬盤空間。
但就像現實生活有願意花錢收廢品,現在大 AI 公司想開始花錢「收廢片」了。
1 月 11 日,據外媒報道,Open AI、Google、Moonvalley 等公司正在購買視頻創作者們拍攝但未使用的「廢片」。⠩똨‡ 4K、無人機、3D 動畫素材,1 - 4 美元(約合 7.3 - 30 元)一分鍾⠯‚† YouTube、TikTok、Instagram 等網絡視頻製作的素材 1 - 2 美元(約 7.3 - 15 元)一分鍾。
這麽看,隻要廢片質量足夠好,一個小時的廢片最高能賣 1800 元,可能比平台給 Up 主的分成還高。
01 AI 巨頭,是真的「餓了」
為什麽這些科技公司,要花錢買用戶拍了不用的廢片?
原因很簡單:⠨斩 𘦓š不夠用了⠣€‚
生成式視頻模型、自動駕駛係統甚至機器人訓練,都需要大量的視頻作為訓練數據。而優質視頻不僅創作門檻高,在 AI 時代的版權劃分也很模糊。
廣告、電影公司的版權價格昂貴,網絡平台通常也隻有發行權而非使用權,和導演及製作團隊簽署的版權合同裏,也鮮少涉及到 AI 使用權的條款。
視頻網站同理,如果視頻模型想合法抓取 YouTube 的視頻,那應該聯係 YouTube 還是 YouTuber?這同樣是 AI 時代還沒解決的版權灰色問題。
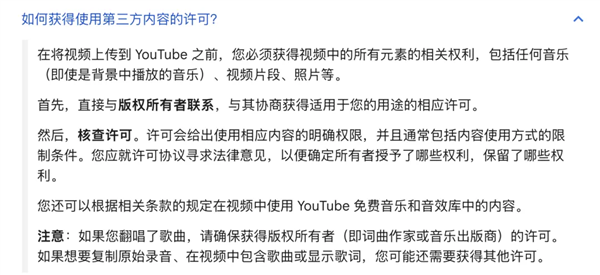 YouTube 也沒有第三方內容的使用許可權|圖源:YouTube
YouTube 也沒有第三方內容的使用許可權|圖源:YouTube2024 年 4 月美國眾議員提出的《生成式 AI 版權披露法案》,要求數據集製作者向注冊員提交「任何受版權保護的作品的充分詳細摘要」,否則將麵臨罰款。
在此背景下,Open AI、Google 還有其他 AI 公司就想到了「不買成片買廢片」的方式。
不過 AI 大公司並不直接和創作者對接,而是通過第三方專業公司去聯係平台和創作者⠯€‘隻付錢。怎麽談、找誰買、買回來怎麽用,這些都由中介公司和平台協商。
幾家中介公司表示,目前已經買了 500 多萬美元的素材,對接的 AI 公司多達 17 家,包括 OpenAI、Meta、微軟等。
AI 公司買回來後也不能亂用,由第三方專業公司做「中介擔保」限製了廢片的使用範圍:AI 公司不能創建創作者的數字分身;不能在 AI 模型裏重現專屬創作者的 AI 場景,比如直接生成某個 Up 主固定的背景或是用 ta 的經典梗、口頭禪等;不能用有損創作者聲譽的方式使用素材。
 對網紅 YouTuber 而言,臉是「身份標識」|圖源:PewDiePie
對網紅 YouTuber 而言,臉是「身份標識」|圖源:PewDiePieYouTube 在上個月也加入了類似的新功能:YouTuber 自行決定 AI 是否能抓取自己的視頻內容,甚至可以選擇授權的 AI 公司(當然也可以全選)。不過目前 YouTube 還沒有給出授權費用的政策。
 授權名單中有十八家主流 AI 公司|圖源:YouTube
授權名單中有十八家主流 AI 公司|圖源:YouTube02 視頻模型的軍備競賽
互聯網內容的發展,隨著帶寬和信息量的增長,軌跡從文字逐漸轉向視頻,大模型也是如此。
視頻模型成為過去一年大模型最卷的賽道,很多 AI 公司更進一步,直接開始卷可以生成動態場景的「世界模型」,但無論哪種模型,數據養料都離不開視頻。於是各大 AI 公司紛紛開始了軍備競賽,誰能拿到更多的視頻數據,誰的視頻模型可能就會更好。
在前不久的 CES 2025 上,英偉達發布了世界基礎模型平台 Cosmos。據介紹,Cosmos 經過了 2000 萬小時的視頻訓練量。然而英偉達在去年就曾被 404 Media 爆出,在未經授權的前提下,違規抓取了大量 YouTube 和 Netflix 的視頻以訓練「內部名稱為 Cosmos 的產品」。
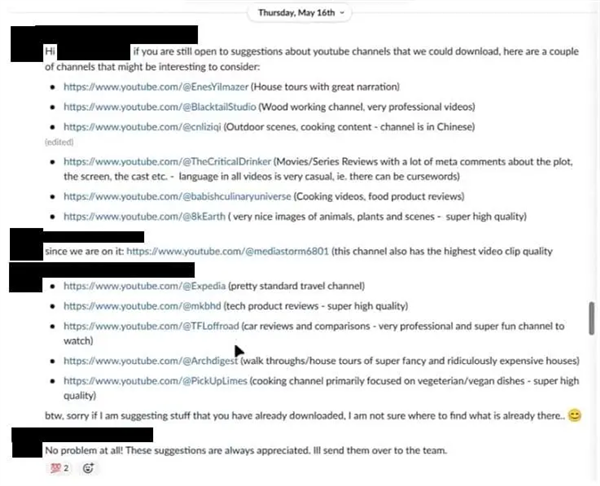 英偉達內部在 Slack 的聊天記錄|圖源:404 Media
英偉達內部在 Slack 的聊天記錄|圖源:404 Media據爆出的英偉達內部聊天記錄,英偉達的 AI 科學家和高管匯總了大量 YouTube 精選視頻數據集用於模型訓練,包括一個名為 HD- VG-130M 的數據集,該數據集由北大的研究人員構建,包含 1.3 億個 YouTube 數據,使用權限僅限於學術研究。
在被質疑「YouTube 服務條款禁止下載,數據也隻能用於研究目的」後,英偉達高管表示「受版權保護的數據能否用於訓練,目前是一個懸而未決的法律問題……在大語言模型上,我相信我們的法律團隊已經批準了這種做法,因此也可能會批準視頻訓練。」
在英偉達之前,OpenAI 的視頻大模型 Sora 已經被 YouTube 點名批評了。正在和 OpenAI 打官司的《紐約時報》率先報道稱,OpenAI 采集了超一百萬小時的 YouTube 視頻用來訓練 GPT-4。
而對 Sora 訓練數據來源,當時的 OpenAI 首席技術官(已離職)Mira Murati 直言「實際上,我也不確定」YouTube CEO Neal Mohan 回應稱「如果 OpenAI 使用 YouTube 視頻來訓練 Sora,就明確違反了 YouTube 的使用條款。」
同樣的態度,YouTube 又把這段采訪發給了 404 Media,回應了一次英偉達。
也有視頻模型另辟蹊徑,將在未來兩個月內公布的新視頻模型「Marey」要做行業裏「最幹淨」的,他們號稱全部訓練數據都拿到了授權,而且 Marey 的目標用戶就是好萊塢和整個電影行業的大型工作室。
 圖源:Moonvalley
圖源:Moonvalley這是因為電影不僅是視頻質量素材的巔峰,也是對版權規範最嚴格的視頻領域。
對網絡視頻創作者而言,廢片本身的歸宿就是備份硬盤甚至回收站,如今有大公司願意出錢讓「廢片再利用」,如果這種模式能持續運轉,也不失為對小創作者的一種營收手段。
對更大牌的「創作者」,比如電影公司、製片廠而言,技術早已滲透甚至改造了電影行業,從 CGI 生成、虛擬製作到 AI 合成語音、麵部去老化等等,AI 無非是一種提高影視製作效率的新技術手段。
但無論大小創作者,或許對 AI 視頻生成都有著「殺雞取卵」的警惕感。試想,當一個創作者源源不斷地把自己的廢片賣給 AI 模型,當 AI 模型已經足夠以假亂真的時候,我們是否還真的需要一個具體的創作者出鏡?當 AI 可以生成電影級空鏡頭,極具視覺衝擊的特效後,電影行業還是否需要技術高超的攝影師、數字特效製作者……
「學習你,追趕你,替代你」這是每一個創作者麵對生成式 AI 的進化時,都難以避免的恐懼。隻能自我安慰道:在擋不住的 AI 浪潮下,廢片還能賣錢,這總比免費當個「數據提款機」要強吧。

文章发布:2025-07-05 07:24:59






评论列表
該公司於2015年6月首次提交IPO招股書。
索嘎